Welcome to E-spec.
Python pip | Python
2021-02-15 21:58:30 Менеджер пакетов PIP.Pip является стандартным менеджером пакетов в Python.
команда для обновления pip:
python -m pip install --upgrade pipКоманды PIP
Синтаксис pip выглядит следующим образом: pip + команда + доп. опции
pip <command> [options]Со всеми командами pip можно ознакомиться, выполнив pip help . Информацию по конкретной команде выведет pip help <command>. Рассмотрим команды pip:
pip install package-name- устанавливает последнюю версию пакета;pip install package-name==4.8.2- устанавливает пакет версии 4.8.2;pip install package-name --upgrade- обновляет версию пакета;pip download- скачивает пакеты;pip uninstall- удаляет пакеты;pip freeze- выводит список установленных пакетов в необходимом формате ( обычно используется для записи вrequirements.txt);pip list- выводит список установленных пакетов;pip list --outdated- выводит список устаревших пакетов;pip show- показывает информацию об установленном пакете;pip check- проверяет установленные пакеты на совместимость зависимостей;pip search- по введенному названию, ищет пакеты, опубликованные в PyPI;pip wheel- собирает wheel-архив по вашим требованиям и зависимостям;pip hash- Вычисляет хеши архивов пакетов;pip completion- вспомогательная команда используется для завершения основной команды;pip help- помощь по командам.
Для работы парсера в новом месте (например на компьютере другого разработчика или на удаленном сервере) необходимо затянуть файлы из системы контроля версий и выполнить команду:
pip install -r requirements.txtКоманда pip list --outdated выведет список всех устаревших пакетов. Обновить отдельно выбранный пакет поможет команда:
pip install package-name --upgradeОднако бывают ситуации, когда нужно обновить сразу все пакеты из requirements.txt. Достаточно выполнить команду:
pip install -r requirements.txt --upgradeДля удаления пакета выполните:
pip uninstall package-nameДля удаления всех пакетов из requirements.txt:
pip uninstall -r requirements.txt -yНеобычные сайты | Разное
2021-01-14 05:02:07 Интересные и необычные сайты https://pisongs.com/ Алгоритм создания музыки был составлен для создания музыки с использованием первого миллиарда цифр числа пи (π). Эти цифры служат «сигналами поворота», используемыми для определения каждого музыкального выражения в песне. Каждая цифра (3,1415 ...) отвечает за оркестровку примерно четырех секунд музыки. Электронные инструменты и звуковые образцы были подготовлены композитором заранее.
https://pisongs.com/ Алгоритм создания музыки был составлен для создания музыки с использованием первого миллиарда цифр числа пи (π). Эти цифры служат «сигналами поворота», используемыми для определения каждого музыкального выражения в песне. Каждая цифра (3,1415 ...) отвечает за оркестровку примерно четырех секунд музыки. Электронные инструменты и звуковые образцы были подготовлены композитором заранее.
Поскольку числа в пи никогда не повторяются, каждый из миллиона часов в каждой песне на самом деле уникален. Если вы перенесетесь в произвольно отдаленный момент в песне, вы практически гарантированно обнаружите, что слушаете то, что никто другой, включая самого композитора, никогда раньше не слышал.
Библиотеки Python | Python
2020-12-21 12:14:25 Библиотеки Python, которые могут пригодиться.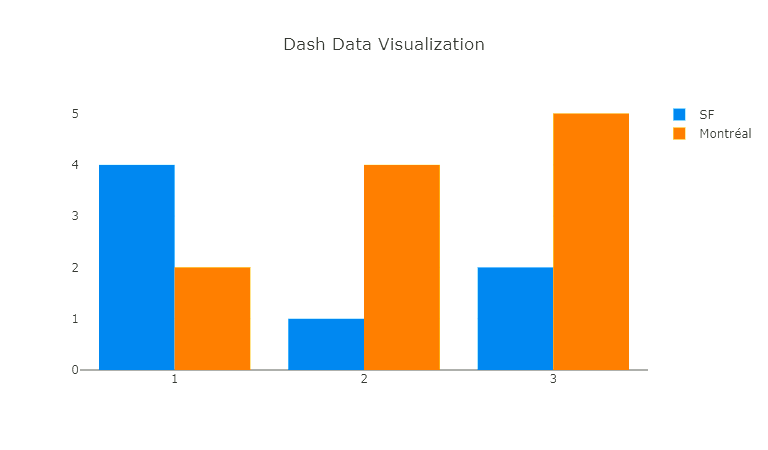 Dash
Dash
Dash появился не так давно. Это идеальное решение для создания приложений по визуализации данных на чистом Python. Пакет крайне полезен для всех, кто работает с данными. Dash — это смесь Flask, Plotly.js и React.js.
Dash позволяет быстро разместить данные на красивом дашборде, не прикасаясь к JavaScript.
pyQT.
Графический инструментарий для Python. Windows: PyQt можно скачать здесь. В комплекте с ним идёт Qt Designer.
wxPython.
Графический пользовательский интерфейс для Python. Позволяет писать великолепные приложения с минимальными затратами сил. Windows and macOS :
pip install -U wxPython Prettytable
Библиотека от GoogleCode.
Prettytable остаётся отличной библиотекой для формирования красивого вывода в терминал:
from prettytable import PrettyTable
table = PrettyTable(["животное", "свирепость"])
table.add_row(["Оборотень", 100])
table.add_row(["Гризли", 87])
table.add_row(["Кролик из Кэрбенног", 110])
table.add_row(["Кот", -1])
table.add_row(["Утконос", 23])
table.add_row(["Дельфин", 63])
table.add_row(["Альбатрос", 44])
table.sort_key("свирепость")
table.reversesort = True
+----------------------+------------+
| животное | свирепость |
+----------------------+------------+
| Кролик из Кэрбенног | 110 |
| Оборотень | 100 |
| Гризли | 87 |
| Дельфин | 63 |
| Альбатрос | 44 |
| Утконос | 23 |
| Кот | -1 |
+----------------------+------------+Wget
Рекурсивно скачать сайт, получить со страницы все изображения? Wget - хороший помощник для решения этих задач.
import wget
wget.download("http://www.cnn.com/")
# 100% [............................................................................] 280385 / 280385
Sh
sh импортирует в Python команды shell в виде функций. Это – удобная возможность, как сделать что-то с помощью bash, но не помните, как это реализуется на Python (например, рекурсивный поиск по файлам).
from sh import find
find("/tmp")
/tmp/foo
/tmp/foo/file1.json
/tmp/foo/file2.json
/tmp/foo/file3.json
/tmp/foo/bar/file3.jsonProgressbar
Выводит прогрессбар. Получить ее можно тут.
from progressbar import ProgressBar
import time
pbar = ProgressBar(maxval=10)
for i in range(1, 11):
pbar.update(i)
time.sleep(1)
pbar.finish()
# 60% |######################################################## |Colorama
Если уж вы занимаетесь добавление прогрессбаров в свои программы, то, может, стоит добавить ещё немного цвета? Справиться с этим вам поможет Colorama.
Colorama
Uuid
Наверняка вам приходилось генерировать для пользователей ID, или рассылать покупателям промокоды, или делать ещё что-то, где нужно создать уникальные последовательности. UUID вам в этом поможет:
import uuid
print uuid.uuid4()
# e7bafa3d-274e-4b0a-b9cc-d898957b4b61Сбор данных
Большинство проектов Data Analytics начинаются со сбора и извлечения данных. Иногда набор данных может быть предоставлен, когда вы работаете в определенной компании, чтобы решить существующую проблему. Однако данные могут быть не готовы, и вам может потребоваться собрать их самостоятельно. Наиболее распространенным сценарием является необходимость сканирования данных из Интернета.
Скрап / Scrapy
Scrapy, вероятно, самая популярная библиотека Python, когда вы хотите написать сканер Python для извлечения информации с веб-сайтов. Например, вы можете использовать его, чтобы извлечь все отзывы о всех ресторанах в городе или собрать все комментарии для определенной категории продуктов на веб-сайте электронной коммерции.
Типичное использование состоит в том, чтобы идентифицировать образец интересной информации, появляющейся на веб-страницах, как с точки зрения шаблонов URL, так и шаблонов XPath. После определения этих шаблонов Scrapy может помочь вам автоматически извлечь всю необходимую информацию и упорядочить ее в структуру данных, такую как таблица и JSON.
Вы можете легко установить Scrapy используя pip
pip install scrapyBeautiful Soup
https://www.crummy.com/software/BeautifulSoup/#Download
Beautiful Soup — это еще одна библиотека Python для очистки веб-контента. Общепринято, что он имеет относительно более короткую кривую обучения по сравнению с Scrapy.
Кроме того, Beautiful Soup будет лучшим выбором для относительно небольших по масштабам задач и / или для разовой работы. В отличие от Scrapy, когда вам нужно разработать собственный «паук» и вернуться к командной строке и запустить его, Beautiful Soup позволяет импортировать его функции и использовать их в режиме онлайн. Поэтому вы даже можете использовать его в своих ноутбуках Jupyter.
Selenium
https://www.selenium.dev/selenium/docs/api/py/index.html
Изначально Selenium разрабатывался как автоматизированная среда веб-тестирования. Однако разработчики обнаружили, что его довольно удобно использовать в качестве веб-скребка.
Селен обычно используется, когда вам нужно получить интересующие данные после взаимодействия с веб-страницами. Например, вам может потребоваться зарегистрировать учетную запись, затем войти в систему и получить содержимое после нажатия некоторых кнопок и ссылок, и эти ссылки определяются как функции JavaScript. В этих случаях обычно нелегко использовать Scrapy или Beautiful Soup для реализации, а Selenium может.
Тем не менее, важно отметить, что Selenium будет работать намного медленнее, чем обычные библиотеки. Это потому, что он фактически инициализирует веб-браузер, такой как Chrome, а затем имитирует все действия, определенные в коде.
Поэтому, когда вы имеете дело с шаблонами URL и XPath, используйте Scrapy или Beautiful Soup. Выбирайте Selenium, только если это необходимо.
Очистка и преобразование данных
Я предполагаю, что нет необходимости утверждать, насколько важны очистка и преобразование данных в аналитике данных и науке о данных. Кроме того, есть слишком много выдающихся библиотек Python, которые делают это хорошо. Я подберу некоторые из них, которые вы должны знать как Data Scientist или Analyst.
Pandas
Я почти уверен, что перечислять Панд в этом списке нет необходимости. Пока вы имеете дело с данными, вы должны были использовать Панд.
С Pandas вы можете манипулировать данными во фрейме данных Pandas. Есть огромные встроенные функции, которые помогут вам преобразовать ваши данные.
Не нужно слишком много слов. Если вы хотите изучать Python, это библиотека, которую нужно учить.
Numpy
Точно так же Numpy — это еще одна обязательная для изучения библиотека для пользователей языка Python, даже не только для ученых и аналитиков данных.
Это расширило объекты списка Python во всеобъемлющие многомерные массивы. Существует также огромное количество встроенных математических функций для поддержки практически всех ваших потребностей с точки зрения расчета. Как правило, вы можете использовать массивы Numpy в качестве матриц, а Numpy позволит вам выполнять матричные вычисления.
Я полагаю, что многие Data Scientist начнут там скрипты Python следующим образом
Итак, несомненно, что эти две библиотеки, вероятно, самые популярные в сообществе Python.
Spacy
Spacy, вероятно, не так знаменит, как предыдущие. В то время как Numpy и Pandas являются библиотеками, работающими с числовыми и структурированными данными, Spacy помогает нам преобразовывать свободный текст в структурированные данные.
Spacy — одна из самых популярных библиотек NLP (обработка естественного языка) для Python. Представьте себе, что, когда вы удалили множество обзоров продуктов с веб-сайта электронной коммерции, вы должны извлечь полезную информацию из этого свободного текста, прежде чем сможете их проанализировать. Spacy имеет множество встроенных функций, таких как рабочий токенизатор, распознавание именованных объектов и обнаружение части речи.
Кроме того, Spacy поддерживает множество различных человеческих языков. На его официальном сайте заявлено, что он поддерживает более 55.
Визуализация данных
Визуализация данных является абсолютно необходимой потребностью в аналитике данных. Нам нужно визуализировать результаты и результаты и рассказать историю данных, которую мы нашли.
Matplotlib
Matplotlib — самая полная библиотека визуализации данных для Python. Кто-то говорит, что Матплотлиб безобразен. Однако, на мой взгляд, как, вероятно, самая базовая библиотека визуализации в Python, Matplotlib предоставляет большинство возможностей для реализации вашей идеи визуализации. Это так же, как разработчики JavaScript могут предпочесть различные виды библиотек визуализации, но когда есть много настраиваемых функций, которые не поддерживаются этими библиотеками высокого уровня, D3.js должен быть вовлечен.
Plotly
Честно говоря, хотя я считаю, что Matplotlib — это необходимая для изучения библиотека для визуализации, в большинстве случаев я бы предпочел использовать Plotly, потому что она позволяет нам создавать самые причудливые графики с наименьшим количеством строк кода.
Независимо от того, хотите ли вы построить трехмерный поверхностный график, точечный график на основе карты или интерактивный анимированный график, Plotly может выполнить требования в короткие сроки.
Он также предоставляет диаграмму студии, которую вы можете загрузить свою визуализацию в онлайн-хранилище, которое поддерживает дальнейшее редактирование и сохранение.
Моделирование данных
Когда аналитика данных приходит к моделированию, мы обычно отсылаем ее к Advanced Analytics. В настоящее время машинное обучение уже не является новой концепцией. Python также считается самым популярным языком для машинного обучения. Конечно, есть много выдающихся библиотек, поддерживающих это.
Scikit Learn
Прежде чем погрузиться в «глубокое обучение», Scikit Learn должна стать библиотекой Python, с которой вы начнете свой путь в машинном обучении.
Scikit Learn имеет 6 основных модулей, которые делают
- Предварительная обработка данных
- Уменьшение размеров
- регрессия
- классификация
- Кластеризация
- Выбор модели
Я уверен, что Data Scientist, который прибил Scikit Learn, уже должен считаться хорошим Data Scientist.
PyTorch
PyTorch создан Facebook и имеет открытый исходный код как фреймворк взаимного машинного обучения для Python.
По сравнению с Tensorflow, PyTorch более «питоничен» с точки зрения синтаксиса. что также сделало PyTorch немного легче в освоении и использовании.
Наконец, в качестве библиотеки для углубленного изучения PyTorch имеет очень богатый API и встроенные функции, помогающие ученым быстро обучать своим моделям глубокого обучения.
Tensorflow
Tensorflow — еще одна библиотека машинного обучения для Python, созданная Google.
Одна из самых популярных функций Tensorflow — это графики потоков данных на Tensorboard. Последняя представляет собой автоматически сгенерированную веб-панель управления, отображающую потоки и результаты машинного обучения, что чрезвычайно полезно для целей отладки и представления.
Распознавание аудио и изображений
Машинное обучение не только по цифрам, но также может помочь с аудио и изображениями (видео рассматривается как серия кадров). Поэтому, когда мы имеем дело с этими мультимедийными данными, этих библиотек машинного обучения будет недостаточно. Вот некоторые популярные библиотеки распознавания аудио и изображений для Python.
Librosa
https://librosa.github.io/librosa/
Librosa — очень мощная библиотека Python для обработки звука и голоса. Его можно использовать для извлечения различных видов функций из аудио-сегментов, таких как ритм, ритм и темп.
С помощью Librosa эти чрезвычайно сложные алгоритмы, такие как сегментация Лапласа, могут быть легко реализованы в несколько строк кода.
OpenCV
OpenCV — наиболее широко используемая библиотека для распознавания изображений и видео. Не будет преувеличением сказать, что OpenCV позволяет Python заменить Matlab с точки зрения распознавания изображений и видео.
Он предоставляет различные API и поддерживает не только Python, но также Java и Matlab, а также выдающуюся производительность, которая заслуживает высокой оценки как в отрасли, так и в научных исследованиях.
Web
Не забывайте, что Python широко использовался в веб-разработке, прежде чем он стал популярным в области науки о данных. Итак, есть также много отличных библиотек для веб-разработки.
Джанго — Django
https://www.djangoproject.com/
Если вы хотите использовать Python для разработки бэкэнда Web-сервиса, Django всегда лучший выбор. Он спроектирован как высокоуровневая инфраструктура, которая может создать веб-сайт всего за несколько строк кода.
Он напрямую поддерживает большинство популярных баз данных, чтобы сэкономить ваше время на настройку соединений и разработку модели данных. Вы бы сосредоточились только на бизнес-логике и никогда не беспокоились о манипуляциях CURD с Django, потому что это основанная на базе данных структура.
Flask
https://flask.palletsprojects.com/
Flask — это облегченная среда веб-разработки на Python. Наиболее ценной особенностью является то, что он может быть легко настроен с любыми конкретными требованиями очень легко и гибко.
Многие другие известные библиотеки и инструменты Python, которые предоставляют веб-интерфейс, созданы с использованием Flask, например, Plotly Dash и Airflow, благодаря облегченной функции Flask.
Бесплатные веб-сайты | E-spec
2020-12-21 01:18:46 Полезные сайтыБесплатные веб-сайты
HTML5 UP: Адаптивные шаблоны HTML5 и CSS3.
Bootswatch: Бесплатные темы для Bootstrap.
Templated: Коллекция 845 бесплатных шаблонов CSS и HTML5.
Wordpress.org | Wordpress.com: Бесплатное создание веб-сайта.
Strikingly: Конструктор веб-сайтов.
Layers: Создание сайтов на WordPress.
Bootstrap Zero: Самая большая коллекция бесплатных шаблонов Bootstrap.
Landing Harbor: Продвижение мобильного приложения c помощью бесплатного лендинга.
Python. Основные методы строк | Python
2020-12-16 23:22:45 Рассмотрим основные методы строк, которые мы можем применить в приложениях.isalpha(): возвращает True, если строка состоит только из алфавитных символов
islower(): возвращает True, если строка состоит только из символов в нижнем регистре
isupper(): возвращает True, если все символы строки в верхнем регистре
isdigit(): возвращает True, если все символы строки - цифры
isnumeric(): возвращает True, если строка представляет собой число
startswith(str): возвращает True, если строка начинается с подстроки str
endswith(str): возвращает True, если строка заканчивается на подстроку str
lower(): переводит строку в нижний регистр
upper(): переводит строку в вехний регистр
title(): начальные символы всех слов в строке переводятся в верхний регистр
capitalize(): переводит в верхний регистр первую букву только самого первого слова строки
lstrip(): удаляет начальные пробелы из строки
rstrip(): удаляет конечные пробелы из строки
strip(): удаляет начальные и конечные пробелы из строки
ljust(width): если длина строки меньше параметра width, то справа от строки добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по левому краю
rjust(width): если длина строки меньше параметра width, то слева от строки добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по правому краю
center(width): если длина строки меньше параметра width, то слева и справа от строки равномерно добавляются пробелы, чтобы дополнить значение width, а сама строка выравнивается по центру
find(str[, start [, end]): возвращает индекс подстроки в строке. Если подстрока не найдена, возвращается число -1
replace(old, new[, num]): заменяет в строке одну подстроку на другую
split([delimeter[, num]]): разбивает строку на подстроки в зависимости от разделителя
join(strs): объединяет строки в одну строку, вставляя между ними определенный разделитель
Например, если мы ожидаем ввод с клавиатуры числа, то перед преобразованием введенной строки в число можно проверить, с помощью метода isnumeric() введено ли в действительности число, и если так, то выполнить операцию преобразования:
string = input("Введите число: ")
if string.isnumeric():
number = int(string)
print(number)
Проверка, начинается или оканчивается строка на определенную подстроку:
file_name = "hello.py"
starts_with_hello = file_name.startswith("hello") # True
ends_with_exe = file_name.endswith("exe") # False
Удаление пробелов в начале и в конце строки:
string = " hello world! " string = string.strip() print(string) # hello world!
Дополнение строки пробелами и выравнивание:
print("iPhone 7:", "52000".rjust(10))
print("Huawei P10:", "36000".rjust(10))
Консольный вывод:
iPhone 7: 52000 Huawei P10: 36000
Поиск в строке
Для поиска подстроки в строке в Python применяется метод find(), который возвращает индекс первого вхождения подстроки в строку и имеет три формы:
find(str): поиск подстроки str ведется с начала строки до ее концаfind(str, start): параметр start задает начальный индекс, с которого будет производиться поискfind(str, start, end): параметр end задает конечный индекс, до которого будет идти поиск
Если подстрока не найдена, метод возвращает -1:
welcome = "Hello world! Goodbye world!"
index = welcome.find("wor")
print(index) # 6
# поиск с 10-го индекса
index = welcome.find("wor",10)
print(index) # 21
# поиск с 10 по 15 индекс
index = welcome.find("wor",10,15)
print(index) # -1
Замена в строке
Для замены в строке одной подстроки на другую применяется метод replace():
replace(old, new): заменяет подстроку old на newreplace(old, new, num): параметр num указывает, сколько вхождений подстроки old надо заменить на new
phone = "+1-234-567-89-10"
# замена дефисов на пробел
edited_phone = phone.replace("-", " ")
print(edited_phone) # +1 234 567 89 10
# удаление дефисов
edited_phone = phone.replace("-", "")
print(edited_phone) # +12345678910
# замена только первого дефиса
edited_phone = phone.replace("-", "", 1)
print(edited_phone) # +1234-567-89-10
Разделение на подстроки
Метод split() разбивает строку на список подстрок в зависимости от разделителя. В качестве разделителя может выступать любой символ или последовательность символов. Данный метод имеет следующие формы:
split(): в качестве разделителя используется пробелsplit(delimeter): в качестве разделителя используется delimetersplit(delimeter, num): параметр num указывает, сколько вхождений delimeter используется для разделения. Оставшаяся часть строки добавляется в список без разделения на подстроки
text = "Это был огромный, в два обхвата дуб, с обломанными ветвями и с обломанной корой"
# разделение по пробелам
splitted_text = text.split()
print(splitted_text)
print(splitted_text[6]) # дуб,
# разбиение по запятым
splitted_text = text.split(",")
print(splitted_text)
print(splitted_text[1]) # в два обхвата дуб
# разбиение по первым пяти пробелам
splitted_text = text.split(" ", 5)
print(splitted_text)
print(splitted_text[5]) # обхвата дуб, с обломанными ветвями и с обломанной корой
Соединение строк
При рассмотрении простейших операций со строками было показано, как объединять строки с помощью операции сложения. Другую возможность для соединения строк представляет метод join(): он объединяет список строк. Причем текущая строка, у которой вызывается данный метод, используется в качестве разделителя:
words = ["Let", "me", "speak", "from", "my", "heart", "in", "English"] # разделитель - пробел sentence = " ".join(words) print(sentence) # Let me speak from my heart in English # разделитель - вертикальная черта sentence = " | ".join(words) print(sentence) # Let | me | speak | from | my | heart | in | English
Вместо списка в метод join можно передать простую строку, тогда разделитель будет вставляться между символами этой строки:
word = "hello" joined_word = "|".join(word) print(joined_word) # h|e|l|l|o
Шутка юмора | Разное
2020-12-13 07:36:30 Админ отстрелялся и подводят итоги... Идут стрельбы.
Идут стрельбы.
Дали автоматы, патроны, показали куда стрелять.
Админ отстрелялся, подводят итоги.
Мишень админа чистая.
Командир:
- ??????!!!!!..
Админ, проверяя автомат:
- С моей стороны пули вылетели. Проблемы с вашей стороны..
Страница: 1
Записей на страницу: 21. Всего записей: 6. Страницы: 1